discard/trim — зачем это вашей флеш-памяти?
Intro
А началось все:
Коллеги, достаточно простая задача - на диске создать файловую систему и смонтировать в ОС.
Кто может сделать сейчас?
Соглашаемся и “раздуваем из мухи слона”.
Описание задачи
Освобожден диск ASM /dev/disk/by-id/dm-name-DATA10.
Желательно убедиться в отсутствии операций ввода-вывода по данному диску.
Для хранения экспорта БД необходимо на диске создать файловую систему и смонтировать в ОС.
В кратце про компоненты участвующие в работе:
На сервере установлена 2х портовая HBA QLogic Corp. ISP8324-based 16Gb.
Диски на сервер раздаются с Pure Storage Flash Array/X70.
Внутри ОС диски используются под БД, следовательно наслоение такое:
multipath -> ASM или multipath -> LVM -> FS
Настройки multipath
Ищем наш лун через команду multipath -ll:
1
2
3
4
5
6
7
8
9
10
11
12
[root@dbhost ~]# multipath -ll DATA10
DATA10 (3624a0000861825987890d30a00232312) dm-4 PURE ,FlashArray
size=2.0T features='0' hwhandler='1 alua' wp=rw
`-+- policy='service-time 0' prio=50 status=active
|- 14:0:2:245 sdm 8:192 active ready running
|- 14:0:1:245 sdc 8:32 active ready running
|- 14:0:7:245 sdao 66:128 active ready running
|- 14:0:3:245 sdw 65:96 active ready running
|- 15:0:0:245 sday 67:32 active ready running
|- 15:0:1:245 sdbi 67:192 active ready running
|- 15:0:2:245 sdbs 68:96 active ready running
`- 15:0:3:245 sdcc 69:0 active ready running
Все настройки файла /etc/multipath.conf выполнены согласно рекомендациям производителя СХД, поэтому тут не придраться.
Проверка ввода-вывода
Для проверки использую iostat.
Чтобы не парсить весь вывод multipath -ll в multipathd есть удобная команда форматирования, в которой можно подобрать флаги форматирования вывода:
1
multipathd show wildcards
Допустим, мы хотим мониторить не суммарную нагрузку на multipath-устройство, а посмотреть I/O на каждый путь в отдельности.
1
paths=$(multipathd show paths format "%d %m" | grep -i DATA10 | cut -f1 -d ' ' | xargs echo | tr ' ' '|');
multipaht show paths- выводит все пути всех устройств.format %d %m- где%mвыводит имя multipath-устройства, а%dпуть этого устройства.
Дальше грепаем пути нашего девайса и через cut выбираем только имена путей, через xargs echo убираем ‘\n’ и с помощью tr делаем сразу заготовку под grep.
Убеждаемся что нет никакой активности по путям:
1
iostat -xdN 5 | grep -Ew "$allpaths"
или
1
iostat -xzdN 1 | grep -Ew "$allpaths"
Активности никакой нет, идем дальше.
Oracle ASM
В целом на этом тоже можно бы было закончить, но…
Решил я проверить на всякий случай, что диск точно убрали из ASM.
Oracle ASM (Automatic Storage Management) – основной менеджер хранения для БД Oracle.
AFD (ASM Filter Driver) и ASMLib (Oracle ASM Library) – это дополнительные технологии, которые помогают ASM работать с “сырыми” блочными устройствами.
AFD (ASM Filter Driver) – модуль ядра, “фильтрующий” ввод-вывод для дисков, выделенных под ASM. Он защищает эти диски от посторонних операций (например, случайных mkfs) и упрощает администрирование в кластерах Oracle RAC.
ASMLib (Oracle ASM Library) – библиотека и набор утилит, позволяющих удобно “помечать” и обнаруживать устройства для ASM.
Определить что используется можно через /dev директорию:
- AFD -
/dev/oracleafd/disks/ - ASMLib -
/dev/oracleasm/disks/
Чтобы посмотреть настроенные диски:
- AFD -
asmcmd afd_lsdsk - ASMLib -
oracleasm listdisks
В моем случае на этом сервере настроен AFD, проверяем удалили ли наш диск:
1
2
3
[root@dbhost]# su - oracle
[oracle@dbhost ~]$ . ./ASM1.env
[oracle@dbhost ~]$ asmcmd afd_lsdsk | grep -i DATA10
Отлично, можем идти дальше
mkfs
Следующий этап - это создание файловой системы.
Здесь вспоминается один забавный случай. Мне задали вопрос:
А сколько по времени нормально может делаться mkfs.ext4 для 10 теров?”
В итоге эти 10 ТБ форматировались почти 50 минут. Тогда я догадался, что причина кроется в том, что “под капотом” у нас SSD (или тонкое хранилище), а mkfs.ext4 по умолчанию выполнил операцию discard для всего объёма, что может занять заметное время. Остановимся на этом подробнее.
xfsprogs
Захотелось убедиться, что действительно для той же xfs в исходниках опция discard стоит по умолчанию поэтому, выкачиваю исходники xfsprogs, они мне еще пригодятся.
И идем в xfsprogs-dev/mkfs/xfs_mkfs.c:
1
2
3
4
5
6
7
8
9
10
11
12
...
5010 main(
5011 int argc,
5012 char **argv)
5013{
5014 xfs_agnumber_t agno;
5015 struct xfs_buf *buf;
5016 int c;
5017 int dry_run = 0;
5018 int discard = 1;
5019 int force_overwrite = 0;
...
Видим, что переменная discard = 1; действительно по умолчанию 1.
Далее по коду можно проследить, что переменная зануляется при передаче опции -K:
1
2
3
5142 case 'K':
5143 discard = 0;
5144 break;
В man mkfs.xfs об этом так и сказано:
1
-K Do not attempt to discard blocks at mkfs time.
Для ext4 чтобы отключить сброс блоков нужно форматировать с параметром nodiscard:
1
mkfs.ext4 -E nodiscard
SSD
Подробные описания архитектуры и принципов работы твердотельных накопителей (SSD) легко найти во множестве источников, поэтому углубляться в детали “что такое SSD” мы не будем. Вместо этого коснёмся лишь тех моментов, которые важны для наших дальнейших рассуждений.
Garbage collector
GC (Garbage collector) - это механизм внутренней “уборки” и перераспределения данных во флеш-памяти (NAND). Он решает главную особенность SSD: в NAND-флеш невозможно перезаписать данные напрямую. Сначала нужно стереть весь блок, а уже потом записывать туда новые страницы.
Наименьшая единица записи (write) - это страница (page), обычно размером 4КБ и до 16КБ.
Наименьшая единица стирания (erase) - это блок (block), который включает в себя множество страниц.
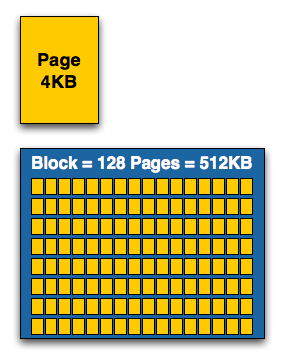 блок и страницы
блок и страницы
Чтобы повторно записать какие-то данные в блок, перед записью, стирается весь блок целиком.
Из-за этого возникает ситуация, когда даже для очистки нескольких “неактуальных” страниц внутри блока может потребоваться считать целый блок, скопировать “живые” страницы в другое место и только потом стереть весь блок.
Например:
Есть блок внутри которого N страниц. Из N страниц “живые” только 2 страницы GC скопирует эти страницы в свободный блок или в блок в который еще пишутся данные (который не до конца заполнен) и очистит текущий блок N целиком.
В результате, даже если “актуальных” данных всего пара страниц в блоке, всё равно нужно полностью его “освободить” (стереть), чтобы записывать новые данные. Это один из факторов, почему у SSD может происходить Write Amplification - это когда приходится перечитывать и перезаписывать даже те данные, которые не менялись, чтобы освободить блок целиком. Чем больше ненужных/устаревших данных приходится копировать и переносить, тем выше нагрузка на SSD и тем быстрее идёт износ ячеек.
Ссылка по теме: ssd garbage collection trim explained
trim/unmap/deallocate/discard
- trim - команда для ATA интерфейса (SATA диски).
- unmap - команда в SCSI протоколе (SCSI/SAS/FC).
- deallocate - команда в NVMe протоколе.
- discard - термин в Linux, используется для операции “сообщить накопителю, что блоки свободны”.
внутри ядра по факту отправляет trim или unmap или deallocate.
Далее под discard считаем что отправляем одну из выше перечисленных команд.
Когда мы записываем какие-то данные на файловую систему, а потом удаляем их, ОС меняет информацию об этом на уровне файловой системы в метаданных. Когда мы делаем rm -f file по сути мы работаем с dentry,inode и так далее, но контроллер никак не сможет понять, что файл удалился на самом деле, поэтому чтобы сообщить контроллеру об этом нужно сделать discard, чтобы помочь GC и уменьшить Write Amplification.
Вот у нас “умная” СХД, у нее есть сжатие и дедупликация, разве она не разберется без нас?
По сути да, разберется, но по факту СХД никак не понять, что вы действительно удалили данные на файловой системе. Особенно это актуально для Thin Provision дисков, когда без discard СХД не освобождает блоки, которые уже не нужны и будет продолжать считать что том целиком записан. Это может вести к тому, что место в пуле (и различные внутренние механизмы оптимизации) будут работать менее эффективно.
Исходя из всего сказанного, будем делать discard.
Основные команды в Linux
В сухом остатке:
- отформатировать раздел в нужную файловую систему
- выполнить discard
- примонтировать раздел в нужное место
- сделать запись в fstab
Отправить discard можно несколькими способами:
1) blkdiscard - работает на уровне блочного устройства (опасно, команда именно стирает все блоки).
2) fstrim - запускается уже на существующей файловой системе.
3) hdparm - работает на уровне блочного устройства (опасно, команда именно стирает все блоки).
4) sg_unmap - работает на уровне блочного устройства (опасно, команда именно стирает все блоки).
5) через опцию монтирования discard - такая опция например в fstab будет говорить о том, что при удалении файла в файловой системе необходимо сразу же отправить команду очистки. Удобно, но дает накладные расходы при интенсивных операциях записи - удаления.
В данном случае правильно было бы сделать blkdiscard, потому что том вышел из ASM полностью и мы хотим использовать его под другие нужды, поэтому можно сообщить хранилищу о том, что LUN полностью свободен. Но мы идем через fstrim, потому что я решил сделать замеры производительности, до discard и после, на замеры через fio времени у меня не было, поэтому я сделал dd, на пару простых операций…
mkfs.xfs
Форматировать будем через ключ -K.
1
2
3
mkfs.xfs -f -K /dev/mapper/DATA10
mkdir /mnt/dbexport
mount /dev/mapper/DATA10 /mnt/dbexport
fstrim
Несколько тестов для эксперимента, перед тестами я сделал тройку прогонов до и после fstrim…
1
2
[root@dbhost dbexport]# dd if=/dev/urandom of=wrt2example.img bs=1M count=4096 conv=fdatasync
4294967296 bytes (4.3 GB) copied, 24.7673 s, 173 MB/s
Теперь делаю fstrim:
1
2
fstrim -v /mnt/dbexport/
/mnt/dbexport/: 2 TiB (2147813519360 bytes) trimmed
Делаю пару тестовых прогонов и повторяю запись:
1
2
[root@dbhost dbexport]# dd if=/dev/urandom of=wrt2example.img bs=1M count=4096 conv=fdatasync
4294967296 bytes (4.3 GB) copied, 18.0744 s, 238 MB/s
fstab
Создаем запись в fstab:
1
/dev/mapper/DATA10 /mnt/dbexport xfs defaults 0 0
Заключение
Вот так я раздул “простую” задачу на несколько страниц.
Спасибо за внимание, подписывайтесь на канал в tg: sysprogch